Harnessing Ingest-Time Eval Fields
Anyone who is familiar with writing search queries in Splunk would admit that eval is one of the most regularly used commands in their SPL toolkit. It’s up there in the league of stats, timechart, and table.
For the uninitiated, eval, just like in any other programming context, evaluates an expression and returns the result. In Splunk, especially when searching, holds the same meaning as well. It is arguably the Swiss Army knife among SPL commands as it lets you use an array of operations like mathematical, statistical, conditional, cryptographic, and text formatting operations to name a few.
Read more about eval here and eval functions here.
What is an Ingest-time Eval?
Until Splunk v7.1, the eval command was only limited to search time operations. Since the release of 7.2, eval has also been made available at index time. What this means is that all the eval functions can now be used to create fields when the data is being indexed – otherwise known as indexed fields. Indexed fields have always been around in Splunk but didn’t have the breadth of capabilities for populating them until now.
Ingest-time eval doesn’t overlap with other common index-time configurations such as data filtering and routing, but only complements it. It lets you enrich the event with fields that can be derived by applying the eval functions on existing data/fields in the event.
One key thing to note is that it doesn’t let you apply any transformation to the raw event data, like masking.
When to use Ingest-time eval
Ingest-time eval can be used in many different ways, such as:
- Adding data enrichment such as a data center field based on a host naming convention
- Normalizing fields such adding a field with a FQDN when the data only contains a hostname
- Using additional fields used for filtering data before indexing
- Performing common calculations such as adding a GB field when there is only a MB field or the length of a field with a string
Ingest-time eval can also be used with metrics. Read more here.
When not to use Ingest-time eval
Ingest-time eval, like index-time field extractions, adds a performance overhead on the indexers or heavy forwarders (whichever is handling the parsing of data based on your architecture) as they will be evaluated on all events of the specific sourcetypes you define it for. Since the new fields are going to be permanently added to the data as they are indexed, the increase in disk space utilization needs to be accounted for as well. Also there is no reverting these new fields as these are indexed/persisted in the index. To remove the data, the ingest-time eval configurations would need to be disabled/deleted and letting the affected data age out.
When using Ingest-time eval also consider the following:
- Validate if the requirement is something that can be met by having an eval function at search time – usually this should be yes!
- Always use a new field name that’s not part of the event data. There should be no conflict with the field name that Splunk automatically extracts with the `KV_MODE=auto` extraction.
- Always ensure you are applying eval on
_rawdata unless you have some index time field extraction that’s configured ahead of it in thetransforms.conf.
Always ensure that your indexers or heavy forwarders have adequately hardware provisioned to handle the extra load. If they are already performing at full throttle, adding an extra step of processing might be that final straw. Evaluate and upgrade your indexing tier specs first if needed.
Now, lets see it in action!
Here is an Example…
Lets assume for a brief moment you are working in Hollywood, with the tiny exception that you don’t get to have coffee with the stars but just work with their “PCI data”. Here’s a sample of the data we are working with. It’s a sample of purchase details that some of my favorite stars made overseas (Disclaimer: The PCI data is fake in case you get any ideas 😉):
2019-12-09 23:46:44,283 - name=Tom Hardy, amount=2620.08063223, currency=USD, dest_country=Tanzania, cc=8888192373782645, cvc=1512019-12-09 23:46:45,284 - name=Ryan Reynolds, amount=4229.66241228, currency=USD, dest_country=Canada, cc=9999047123456789, cvc=1012019-12-09 23:46:48,288 - name=Frances McDormund, amount=6033.83328530, currency=USD, dest_country=Budapest, cc=9999513562353615, cvc=8562019-12-09 23:47:11,320 - name=Daniel Day-Lewis, amount=5603.00466255, currency=USD, dest_country=Iceland, cc=9999463984323578, cvc=0292019-12-09 23:47:21,333 - name=Clint Eastwood, amount=8321.50139290, currency=USD, dest_country=Sri Lanka, cc=8888847290573791, cvc=3472019-12-09 23:47:22,335 - name=Tom Hardy, amount=3773.86328145, currency=USD, dest_country=Tanzania, cc=8888192373782645, cvc=1512019-12-09 23:47:23,336 - name=Jeff Goldblum, amount=9475.63602049, currency=USD, dest_country=Sri Lanka, cc=8888485176493782, cvc=730
Now we are going to create some ingest-time fields:
- Making the name to all upper case (just for the sake of it)
- Rounding off the amount to two decimal places
- Applying a
bankfield based on the starting four digit of the card number - Applying
md5hashing on the card number - Applying a mask to the card number
First things first, lets set up our props.conf for the data with all the recommended attributes defined. What really matters in our case here is the TRANSFORMS attribute.
[finlog]SHOULD_LINEMERGE=falseLINE_BREAKER=([\r\n]+)TRUNCATE=10000TIME_FORMAT=%Y-%m-%d %H:%M:%S,%fMAX_TIMESTAMP_LOOKAHEAD=25TIME_PREFIX=^TRANSFORMS = fineval1, fldext1, fineval2 # order of values for transforms matter
Now let’s define how the transforms.conf should look like. This essentially is the place where we define all our eval expressions. Each expression is comma separated.
[fineval1]INGEST_EVAL= uname=upper(replace(_raw, ".+name=([\w\s'-]+),\stime.*","\1")), purchase_amount=round(tonumber(replace(_raw, ".+amount=([\d\.]+),\scurrency.*","\1")),2)# notice how in each case we have to operate on _raw as name and amount fields are not index-time extracted.[fldext1]REGEX = .+cc=(\d{15,16})FORMAT = cc::"$1"WRITE_META = true[fineval2]# INGEST_EVAL= cc=md5(replace(_raw, ".+cc=(\d{15,16})","\1"))# have commented above as we need not apply the eval to the _raw data. fldext1 here does index time field extraction so we can apply directly on the extracted field as below...
INGEST_EVAL= cc1=md5(cc), bank=case(substr(cc,0,4)=="9999","BNC",substr(cc,0,4)=="8888","XBS",1=1,"Others"), cc2=replace(cc, "(\d{4})\d{11,12}","\1xxxxxxxxxxxx")
All the above settings should be deployed to the indexer tier or heavy forwarders if that’s where the data is originating from.
A couple things to note – you can define your ingest-time eval in separate stanzas if you choose to define them separately in the props.conf. Below is a use case for that. Here I have defined an index time field extraction to extract the value of card number. Then in a separate stanza, I used another ingest-time eval stanza to process on that extracted field. This is a good use case of reusability of regex (instead of applying it on _raw repeatedly) in case you need to do more than one operations on specific set of fields.
Now we need to do a little extra work that’s not common with a search time transforms setting. We have to add all the new fields created above to fields.conf with the attribute INDEXED=true denoting these are index time fields. This should be done in the Search Head tier.
[cc1]INDEXED=true[cc2]INDEXED=true[uname]INDEXED=true[purchase_amount]INDEXED=true[bank]INDEXED=true
The result looks like this:
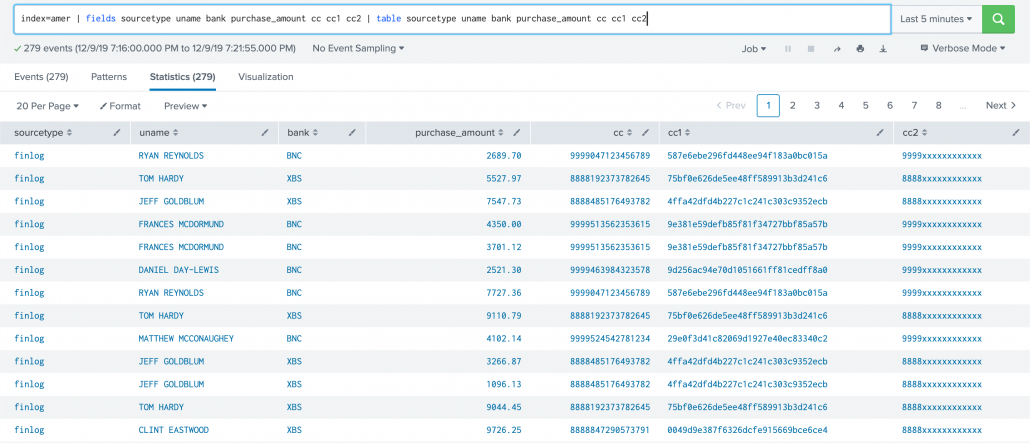
One important note about implementing Ingest-time eval configurations, is that they require manual edits to .conf files as there is no Splunk web option for it. If you are a Splunk Cloud customer, you will need to work with Splunk support to deploy them to the correct locations depending on your architecture.
OK so that’s a quick overview of Ingest-time eval. Hope you now have a pretty fair understanding of how to use them.
Looking to expedite your success with Splunk? Click here to view our Splunk Professional Service offerings.© Discovered Intelligence Inc., 2020. Unauthorised use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.