In early January of this year I was able to attend FloCon 2019 in New Orleans. In this posting, I will provide a little bit of insight into this security conference, some of the sessions that I attended, and detail some of the major data challenges facing security teams.
It was not hard to convince me to go to New Orleans for obvious reasons: the weather is far nicer than Toronto during the winter, cajun food and the chance to watch Anthony Davis play at the Smoothie King Center. I also decided to stay at a hotel off of Bourbon Street which happened to be a great decision. Others attending FloCon decided to arrange accommodations on Bourbon Street ended up needing ear plugs to get a good night’s rest! Enough about that though and let’s talk about the conference itself.
About FloCon
FloCon is geared towards researchers, developers, security experts and analysts looking for techniques to analyze and visualize data for protection and defense of networked systems. The conference is quite small, with a few hundred attendees rather than the 1000s that attend conferences I have attended in the past, like Splunk Conf and the MIT Sloan Conference. However, the smaller number of attendees in no way translated to a worse experience. FloCon was mostly single track (other than the first day), which meant I did not have to reserve my spot for popular session. The smaller number also resulted in greater audience participation.
The first day was split between two tracks: (1) How to be an Analyst and (2) BRO training. I chose to attend the “How to be an Analyst” track. For the first half of the day, participants of the Analyst track were given hypothetical situations which was followed by discussions on hypothesis testing and what kind of data would be of interest to an analyst in order to determine a positive threat. The hypothetical situation in this case was potential vote tampering (remember this is a hypothetical situation). The second half of the day was supposed to be a team game which involved questions and scoring based multiple choice answers. However, the game itself could not be scaled out to the number of participants, therefore the game was completed with all participants working together, which led to some interesting discussions. The game needs some work, but it was interesting to see how different participants thought through the scenarios and how individuals would go about investigating Indicators Of Compromise (IOCs).
The remaining three days saw different speakers present their research on machine learning, applying different algorithms to network traffic data, previous work experience as penetration testers, key performance indicators, etc. The most notable of the speakers being Jason Chan, VP of Cloud Security at Netflix. Despite some of the sessions being heavily research based and with a lot of graphs (some of which I’m sure went over the heads of some of us in attendance), common themes kept arising about the challenges faced by organizations – all of which Discovered Intelligence has encountered on projects. I have identified some of these challenges below.
Challenge: Lack of Data Standardization Breaks Algorithms
I think everyone knows that scrubbing data is a pain. It does not help that companies often change the log format with new releases of software. I have seen new versions break queries because a simple change has cascading effects on the logic built into the SIEM. Changing the way information is presented can also break machine learning algorithms, because the required inputs are no longer available.
Challenge: Under Investing in Fine-Tuning & Re-iterations
Organizations tend to underestimate the amount of time needed to fine-tune queries intended for threat hunting and anomaly detection. The first iteration of a query is rarely perfect and although it may trigger an IOC, analysts will start to realize there are exceptions and false positives. Therefore, overtime teams must fine-tune the original queries to be more accurate. The security team for the Bank of England spends approximately 80% of their time developing and fine-tuning use cases! The primary goal being to eliminate alert fatigue, and to keep everything up-to-date in an ever changing technological world. I do not think there is a team out there that gets “too few” security alerts. For most organizations, the reality is: that there are too many alerts and not enough resources to investigate. Since there are not enough resources, fine-tuning efforts never happen and analysts will begin to ignore alerts which trigger too often.
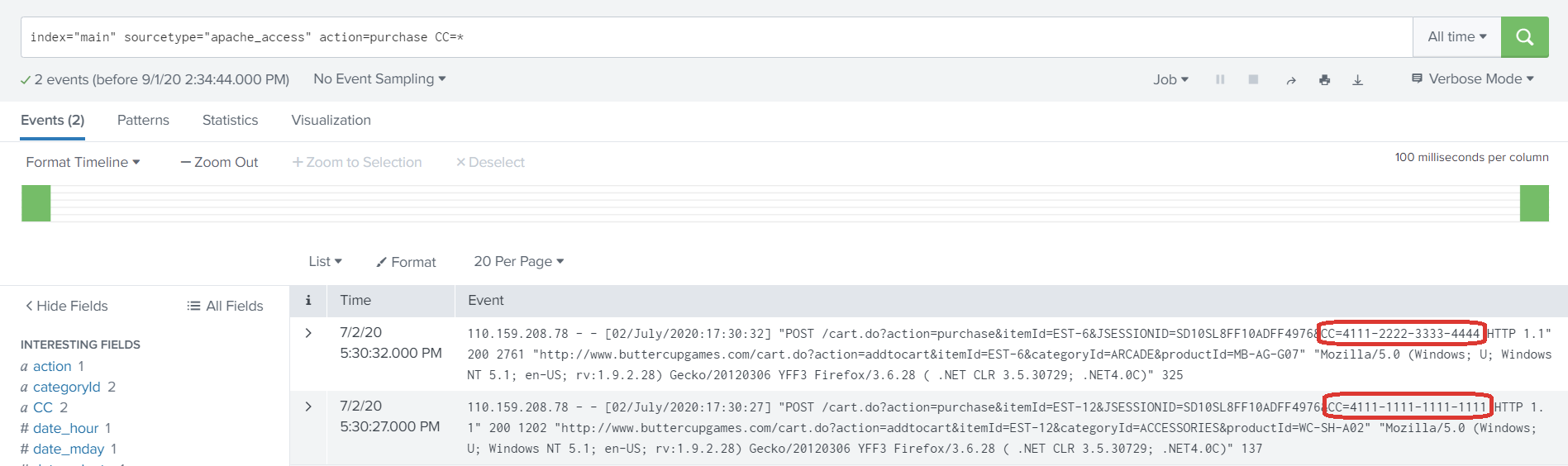
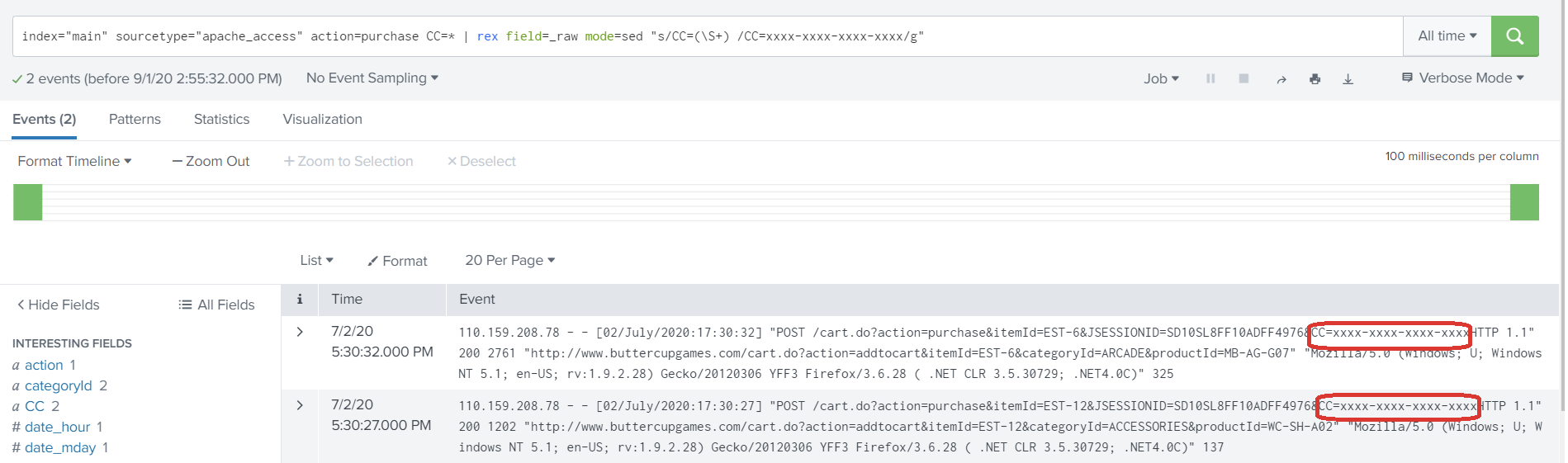
An example of the first iteration of an alert which can generate high volumes is failed authentications to a cloud infrastructure. If the organization utilizes AWS or Microsoft Cloud, they may see a huge number of authentication failures for their users. Why and how? Bad actors are able to identify sign-in names and emails from social media sites, such as LinkedIn or company websites. Given the frequently used standards, there is a good chance that bad actors can guess usernames just based off an individual’s first and last name. Can you stop bots from trying to access your Cloud environment? Unlikely, and if you could, the options are limited. After all, the whole point of Cloud is the ability to access it anywhere. All you can really do is minimize risk by requiring internal employees to use things like multi-factor authentication, biometric data or VPN. At least this way even if a password was obtained a bad actor will have difficulty with the next layer of security. In this type of situation though, alerting on failed authentications alone is not the best approach and creates a lot of noise. Instead, what teams might start to do is correlate authentication failures with users who do not have multi-factor enabled, thereby paying more attention to those who are at greater risk of a compromised account. These queries evolve through re-iteration and fine-turning, something which many organizations continue to under invest in.
Challenge: The Need to Understand Data & Prioritize
Before threats and anomalies can be detected accurately and efforts divided appropriately, teams have to understand their data. For example, if the organization uses multi-factor, how does that impact authentication logs? Which event codes are teams interested in for failed authentications on domain controllers? Is there a list of assets and identities, so teams can at least prioritize investigations for critical assets and personnel with privileged access?
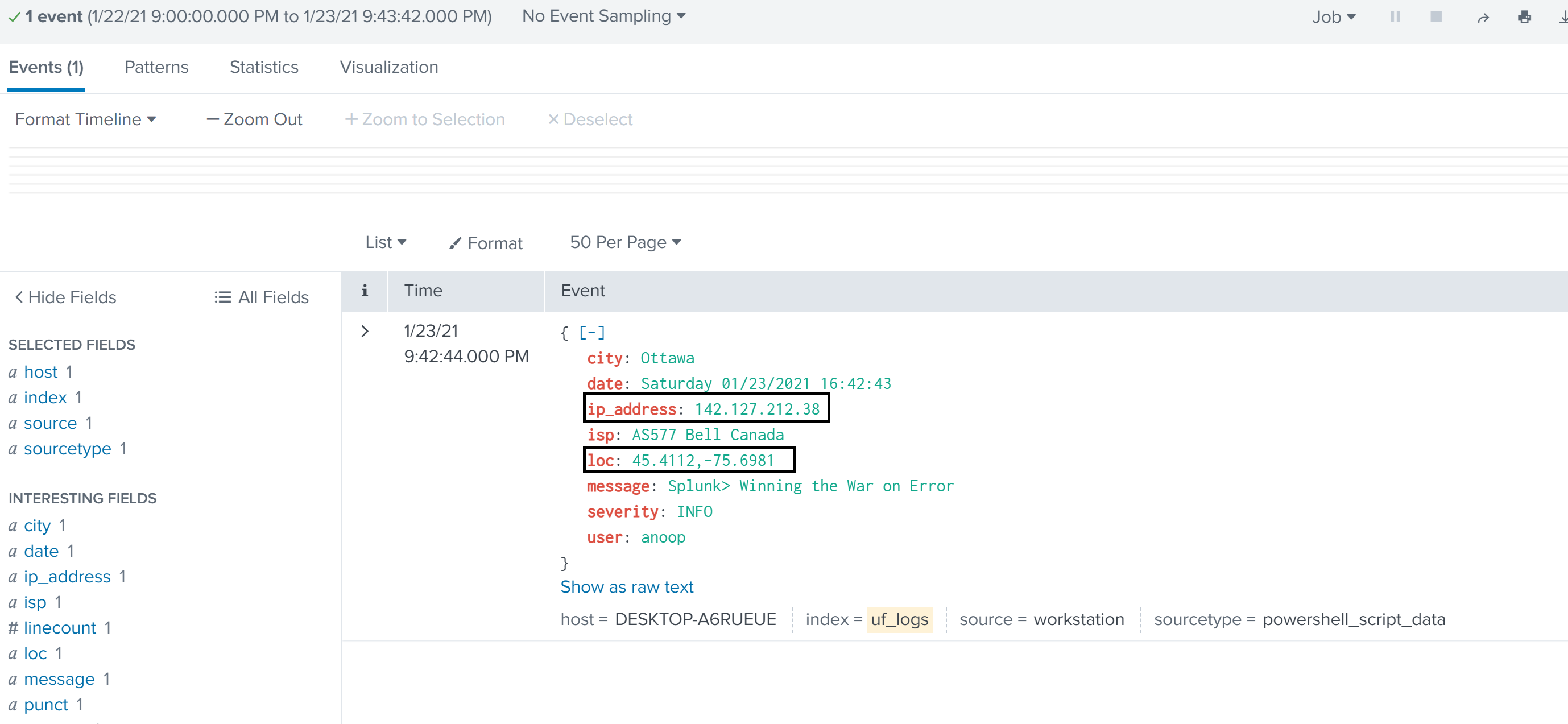
A good example of the need to understand data is multi-factor and authentication events. Let’s say an individual is based out of Seattle and accessing AWS infrastructure requiring Okta multi-factor authentication. The first login attempt will come from an IP in Seattle, but the multi-factor authentication event is generated in Virginia. These two authentication events happen within seconds of each other. A SIEM may trigger an alert for this user because it is impossible for the user to be in both Seattle and Virginia in the given timeframe. Therefore, logic has to built in to the SIEM, so this type of activity is taken into consideration and teams are not alerted.
Challenge: The Security Analyst Skills Gap
Have you ever met an IT, security or dev ops team with too little work or spare time? I personally have not. Most of the time there is too much work and not enough of the right people. Without the right people, projects and tasks get prolonged. As a result, the costs and risks only rise overtime. Finding the right people is a common problem and not one just faced by the security industry, but there is a clearly a gap in the positions available and the skills in the workforce.
Challenge: Marketing Hype Has Taken Over
We hear the words all the time. Machine Learning. Artificial Intelligence. Data Scientists. How many true data scientists have you met? How many organizations are utilizing machine learning outside of manufacturing, telematics and smart buildings? Success stories are presented to us everywhere, but the amount of effort to get to that level of maturity is immense and there is still a lot of work to be done for high levels of automation to become the norm in the security realm.
In most cases, organizations are looking at data for the first time and leveraging new platforms for the first time. They still do not know what normal behaviour looks like in order to determine an event as an anomaly. Even then, how many organizations can efficiently go through a year’s worth of data to baseline behaviour? Do they have the processing power? Can it scale out to the entire organization? Although there is some success a turnkey solution really does not exist. Each organization is unique. It takes time, the right culture, roadmap planning and the right leadership to get to the next level.
Challenge: How Do You Centralize Logs? Understanding the Complete Picture
In order to accomplish sophisticated threat hunting and anomaly detection a number of different data sources must be correlated to understand the complete picture. These sources include AD logs, firewall logs, authentication, VPN, DHCP, network flow, etc. Many of these are high volume data sources so how will people analyze the information efficiently? Organizations have turned to SIEMs to accomplish this. Although SIEMs work well in smaller environments, scaling out appropriately is a significant challenge due to data volumes, a lack of resources (both people and infrastructure) and the lack of training and education for users and senior management.
In most cases, a security investigation begins and analysts start to realize there are missing pieces and missing data sets to get the complete picture of what is happening. At which point, additional data sources must be on-boarded and the fine-tuning process starts again.
Wrap Up and FloCon Presentations
This posting highlights some of the data challenges that are facing security teams today. These challenges are present in all industry verticals, but with the right people and direction companies can begin to mature and automate processes to identify threats and anomalies efficiently. Oh, and did I mention, with our industry leading, security data and Splunk expertise, Discovered Intelligence can help with this!
Overall FloCon was a great learning experience and I hope to be able to attend again some time in the future. The FloCon 2019 presentations are available for review and download here: https://resources.sei.cmu.edu/library/asset-view.cfm?assetid=540074
Looking to expedite your success with Splunk? Click here to view our Splunk Professional Service offerings.
© Discovered Intelligence Inc., 2019. Unauthorised use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.