Getting Started With Splunk’s Machine Learning Toolkit
The Splunk Machine Learning Toolkit (MLTK) assists in applying machine learning techniques and methods against your data. This article discusses how to get started with the MLTK including installation and some initial testing and examples.
The Splunk MLTK includes methods to analyze data include algorithms such as regression, anomaly and outlier detection. These are essential for understanding, modelling and detecting trends in your data not easily identifiable by observation. The Machine Learning Toolkit also enables custom visualization and example datasets to practice your Splunk Processing Language (SPL) commands. It also provides an assistant to create a model for analyzing your data, which helps get you started faster with Machine Learning.
Install the Splunk Machine Learning Toolkit
You must install two apps to properly install and configure the Splunk MLTK, both of which are available on Splunkbase. These apps only need to be installed on your Search Head and you should use the normal app installation process you would follow for any other app.
Step 1 – Install the Python For Scientific Computing Add-on
The first application you need to install is the Python For Scientific Computing add-on. There are three versions, based on your OS, Windows 64-bit and Linux 32/64-bit. Links for all add-on types are provided below:
https://splunkbase.splunk.com/app/2883/ – Windows 64-bit
https://splunkbase.splunk.com/app/2884/ – Linux 32-bit
https://splunkbase.splunk.com/app/2882/ – Linux 64-bit
The Python For Scientific Computing add-on allows Splunk to import python’s scientific, engineering and mathematical libraries for computing statistical tests and data exploration for use with custom Splunk commands.
Step 2 – Install the Machine Learning Toolkit App
The Machine Learning Toolkit app provides all of the dashboards, knowledge objects and custom search commands and can be downloaded here:
https://splunkbase.splunk.com/app/2890/
After the app is installed, Splunk will need to be restarted. Once the restart is completed and you log back into Splunk, the Splunk Machine Learning Toolkit app will be visible on the app bar from the Splunk launcher page.

Use the Machine Learning Toolkit
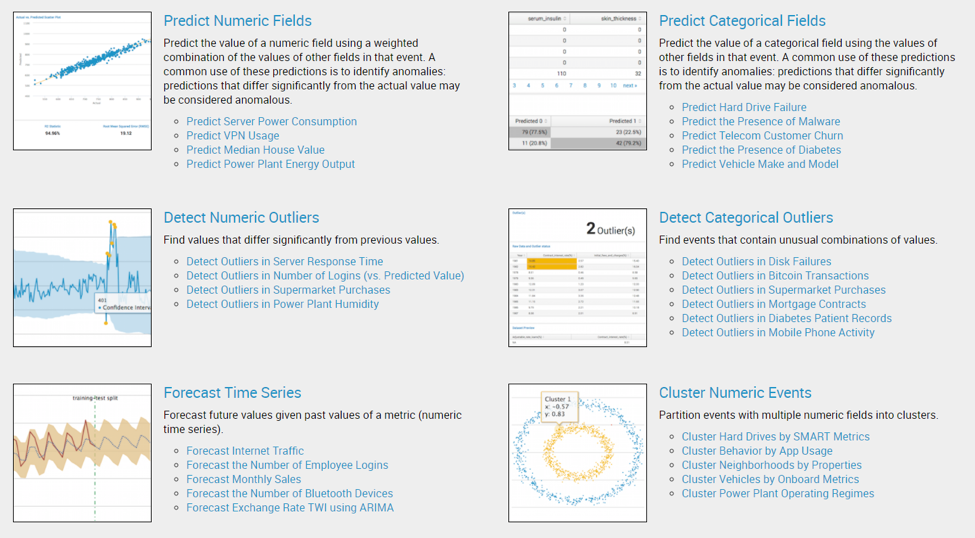
After launching the app, you will be taken to the ‘showcase’ tab of the app by default, which lists the analytical capabilities provided with the app. It also showcases some examples to illustrate how to apply various algorithms to sample datasets.
Test the Machine Learning Toolkit Assistant
Each example in the MLTK demonstrates the analytical capabilities of the toolkit. We will look closely at Forecast Monthly Sales in the Forecast Time Series Section. Click on the example to navigate to an Assistant page, that will allow you to use the forecasting as shown below.
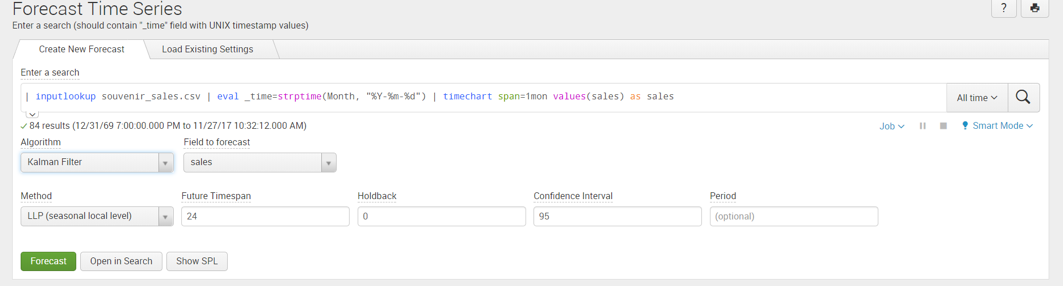
This assistant allows us to select either ‘ARIMA’ or ‘Kalman Filter’, also known as the ‘Linear quadratic estimation’ algorithm, for forecasting and we will adjust the variables to populate for the algorithm. The assistant auto populates the search bar with a sample dataset of monthly sales and adds default values to the variables. The default values can be adjusted based on your forecasting requirements.
Once the variables have been populated click on “Forecast” to calculate the forecasted values.
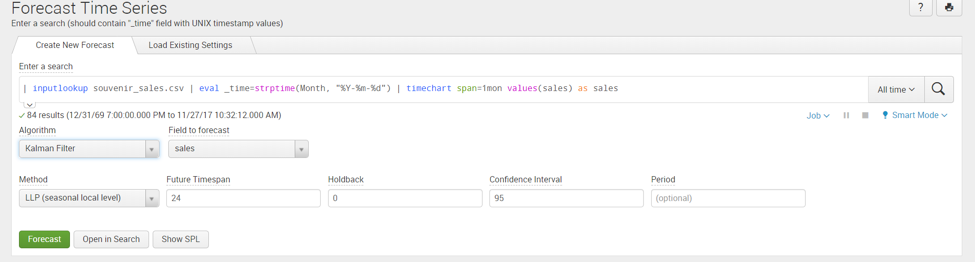
The predicted outcome of the times series data is displayed in a ‘time chart’ visualization.
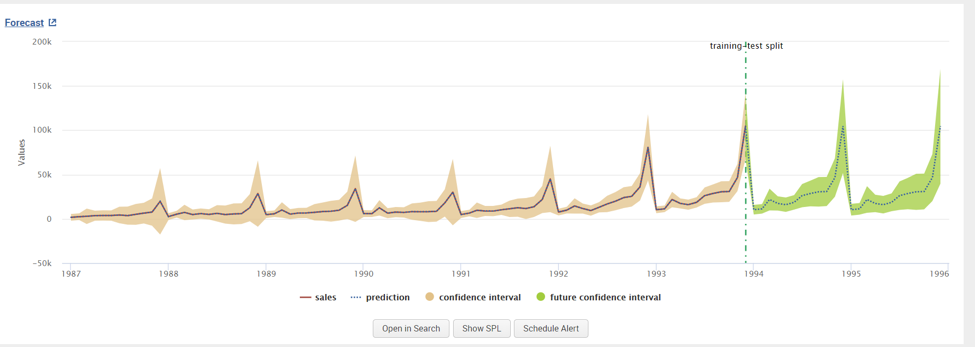
The green highlighted part of the chart is the forecasted monthly sales based on the algorithm. The X-axis in the time series will represent the _time variable while the Y-axis is the field we want to forecast (In this example, Y-axis represents the sales). The MLTK assistant makes it convenient for the Splunk user to executing algorithms for forecasting without complicated mathematical calculations.
To view the Splunk Query executed in the background in in this model, we click on ‘Open in Search’ displaying the commands used in this visualization. The search that powers this visual is:
| inputlookup souvenir_sales.csv | eval _time=strptime(Month, "%Y-%m-%d") | timechart span=1mon values(sales) as sales | predict "sales" as prediction algorithm="LLP" future_timespan="24" holdback="0" lower"95"=lower"95" upper"95"=upper"95" | `forecastviz(24, 0, "sales", 95)`
Machine Learning Search Commands
The Splunk Machine Learning Toolkit contains custom commands, referred to as Machine Learning- Search Processing Language (ML-SPL) that can be utilized to implement statistical modelling. These commands are as follows:
- apply
- deletemodel
- fit
- listmodels
- sample
- summary
A guide to understand the Machine Learning Toolkit Search Commands can be found on Splunk Docs here.
Manage Models
The Models menu in the MLTK app displays the models that the user has access to. It lists how the models are shared, who owns the models and what types algorithms are used. This is a convenient page to list all the models that the user has worked on and if they can be shared. By default, the power and admin roles can modify and set permissions for models.

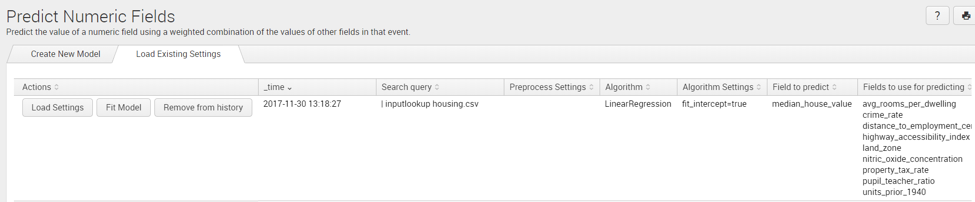
Load Existing Settings
This is a useful feature that stores your history for modelling data. When working on your model, the ‘Load Existing Settings’ saves a history of your model fields used and settings such as; Actions, time, Search Query, Preprocessing Settings, Algorithm, Algorithm Settings, Field to Predict and Fields to use for predicting. We can quickly refer back to any of the previous settings we used during the creation of the model.
Preprocessing
Preprocessing allows you to prepare your data for applying algorithms on it. It creates uniformity for your field based on your model requirements. The preprocessing assistant is found on the same page below the search input when creating a new model.
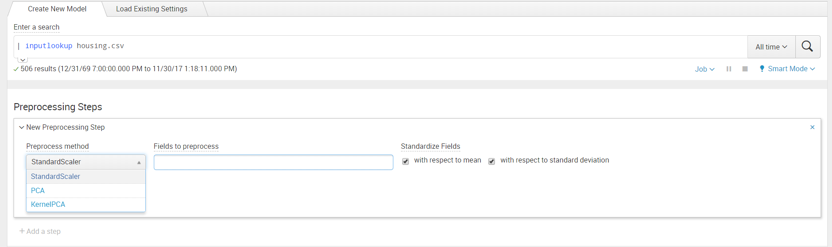
The three algorithms that that are provided in Preprocessing are that can be applied to your numeric fields are:
- Standard Scaler transformation with respect to Mean or Standard Deviation
- Principal Component Analysis (PCA) to convert possibly correlated data to linearly uncorrelated variables called principal components
- Kernel Principal Component Analysis (KernelPCA), is similar to PCA mapping, however it can project data to multi-dimensions and find non-linear dependences in the fields selected from the raw data
When the type of algorithm is picked, we would ‘Apply’ to perform the specified preprocessing. This would create a new field with a prefix ‘SS_’ for Standard Scaler and ‘PC1_’ and ‘PC2_’ for the remaining algorithms. The newly created field can then be used in our model. Preprocessing is a useful step in eliminating the need for manual computation to scale data for applying to the model.
More information on steps to apply as well as information on pre-processing and algorithms can be found on Splunk Docs here.
Stay tuned for more posts about the Machine Learning Toolkit as we take it for a spin and showcase some practical uses for it!
Looking to expedite your success with Splunk? Click here to view our Splunk service offerings.
© Discovered Intelligence Inc., 2018. Unauthorised use and/or duplication of this material without express and written permission from this site’s owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Discovered Intelligence, with appropriate and specific direction (i.e. a linked URL) to this original content.




